Detailed and versatile annotations, structured activity and process understanding, integration with VLMs, and instruction generation enable and facilitate unparalleled opportunities for real-world robotic workflows and training.
Abstract
The Coffee-Making 101 dataset is a richly annotated resource designed to support robotic perception, reasoning, and control in natural environments. Annotated using the Ramblr Data Engine (RDE), the dataset benefits from a scalable annotation workflow that enables the generation of a variety of high-quality, structured labels. The dataset includes dense annotations across objects, activities, relations, and attributes, enabling advanced model training for imitation learning, instruction generation, and vision-language understanding. As robotics moves toward hybrid data strategies - balancing large-scale pretraining with targeted fine-tuning - this dataset exemplifies the critical role of explicit, task-specific labels in achieving grounded, dexterous control.
Introduction
Controlling robots in natural environments requires rich, structured data that supports both generalization and precision. While recent advances in Vision-Language-Action (VLA) models for robotics [1, 2] have demonstrated a new paradigm for real-world reasoning and robotic control, generalizing these capabilities to unseen or unstructured settings remains challenging [3], largely due to the brittleness of policies learned from scarce and poorly-grounded training data [4].
The Coffee-Making 101 dataset, built in the context of the REACT research project, addresses this gap by providing dense, multi-modal annotations tailored for robotic learning. The dataset exemplifies a hybrid data annotation strategy: leveraging scalable automation with human-in-the-loop precision and experience to produce high-fidelity labels. This approach aligns with emerging best practices in robotics R&D [5, 6, 7], where foundational models are pre-trained on broad datasets and fine-tuned using small, high-quality, domain-specific data. Learn more about the broader research context at ramblr.ai/research.
Dataset
The dataset was annotated using the Ramblr Data Engine, which combines human-in-the-loop workflows with a high degree of automation. This approach ensures both precision and scalability in the annotation process. Key features of the RDE are guided labeling using keyframes and anomaly detection, automated video segmentation leveraging SAM 2, and more - check out our feature and tutorial videos. The resulting annotations capture fine-grained task steps, object interactions, and contextual variations, making the dataset particularly valuable for training models in robotic manipulation, task planning, and multimodal understanding.
Figure 1: Distribution of the video length.

The dataset includes:
| Metric | Value |
|---|---|
| Avg. objects per video | 13 |
| Avg. relations per video | 17,275 |
| Avg. attributes per video | 48,882 |
| Avg. activities per video | 9 |
Generally, these versatile annotations can be used to train a diverse set of models:
Image 1: Ramblr Data Engine - Annotated coffee-making video sample. Left: The mask and category overlays of the video segmentation and the corresponding raw frame. Right: Object-object relations within the example frame. Bottom: Timeline with the individual objects (left column), occurrences (x-axis timeline), and relations and attributes (dashed line within object segments).

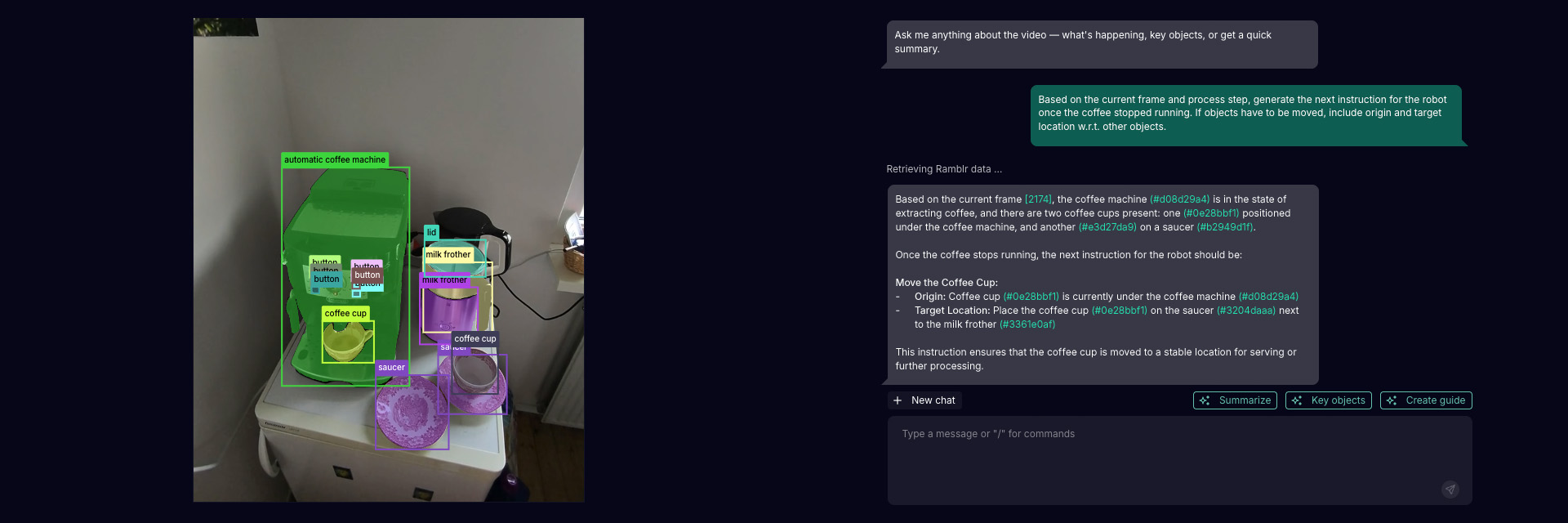
Image 2: Ramblr Data Engine. Example interaction with the annotated data for context understanding in a virtual robot-control scenario. The LLM-generated response can, for example, be used to generate diverse, grounded training data for VLMs.

Conclusion
The RDE facilitates rapid, scalable annotation of high-quality ground truth (GT) labels, as demonstrated with the Coffee-Making 101 dataset. These annotations can be leveraged for model training, serve as structured, machine-readable references for domain-specific processes and their variations, and support ask-me-anything style interactions - such as required for knowledge transfer, onboarding, and contextual assistance.
Future work will focus on enriching datasets with spatial sensor data, including 3D scene reconstructions and the fusion of camera stream information with sparse point clouds. In instruction generation, for instance, incorporating camera pose – i.e., understanding the field of view relative to the scene – enables the creation of spatially-aware, next-step guidance. An illustrative instruction might be: “Rotate 180 degrees to bring the table into view, allowing accurate placement of the coffee cup.”
References
[1] Team, G. R., Abeyruwan, S., Ainslie, J., Alayrac, J. B., Arenas, M. G., Armstrong, T., ... & Zhou, Y. (2025). Gemini robotics: Bringing ai into the physical world. arXiv preprint arXiv:2503.20020.
[2] Zhou, Z., Zhu, Y., Zhu, M., Wen, J., Liu, N., Xu, Z., ... & Feng, F. (2025). Chatvla: Unified multimodal understanding and robot control with vision-language-action model. arXiv preprint arXiv:2502.14420.
[3] Jang, E., Irpan, A., Khansari, M., Kappler, D., Ebert, F., Lynch, C., ... & Finn, C. (2022, January). Bc-z: Zero-shot task generalization with robotic imitation learning. In Conference on Robot Learning (pp. 991-1002). PMLR.
[4] Belkhale, S., Cui, Y., & Sadigh, D. (2023). Data quality in imitation learning. Advances in neural information processing systems, 36, 80375-80395.
[5] Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., ... & Han, K. (2023, December). Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning (pp. 2165-2183). PMLR.
[6] Driess, D., Xia, F., Sajjadi, M. S., Lynch, C., Chowdhery, A., Wahid, A., ... & Florence, P. (2023). Palm-e: An embodied multimodal language model.
[7] Makoviychuk, V., Wawrzyniak, L., Guo, Y., Lu, M., Storey, K., Macklin, M., ... & State, G. (2021). Isaac gym: High performance gpu-based physics simulation for robot learning. arXiv preprint arXiv:2108.10470.