Internal Research and Technology
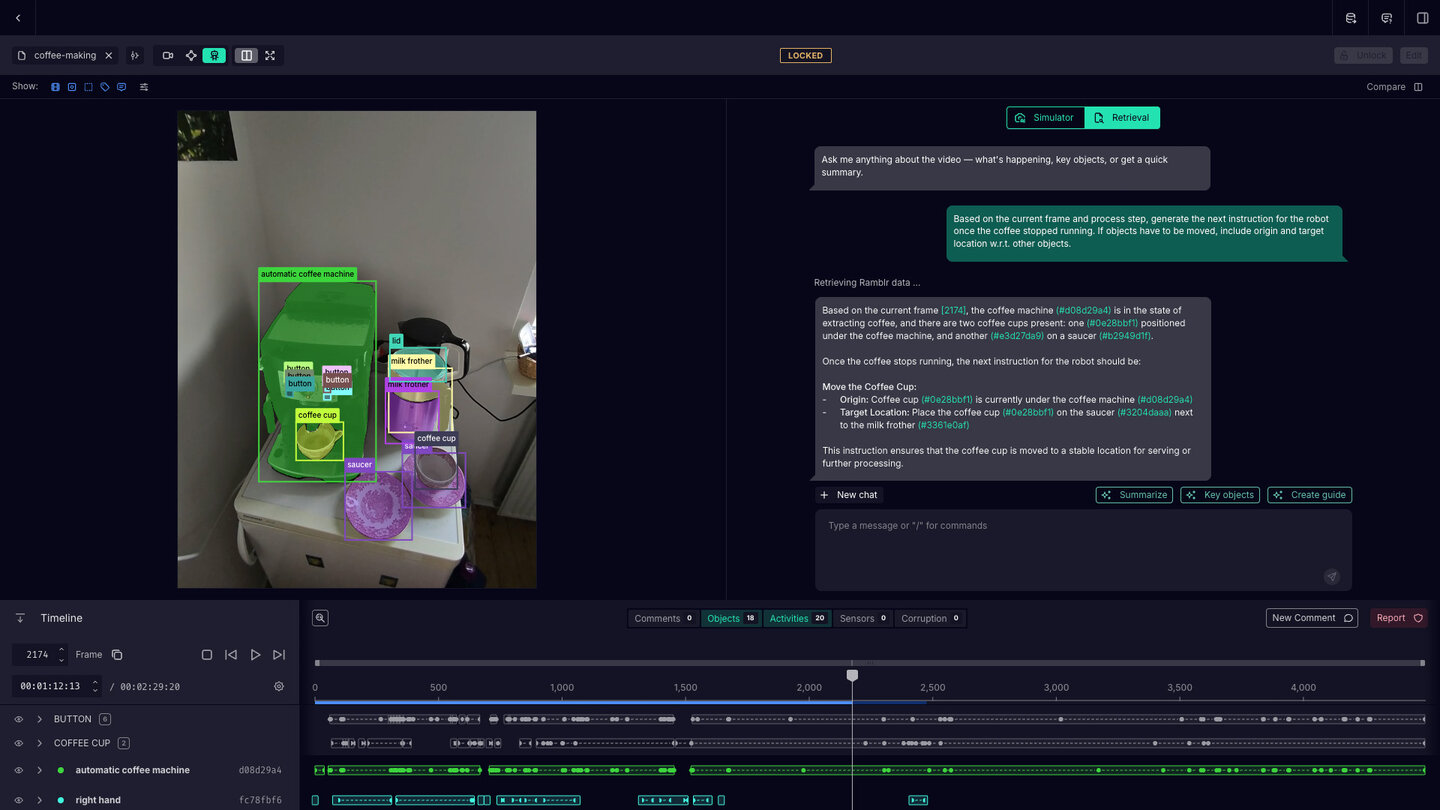
Instruction Generation
The Ramblr Data Engine, which combines low-level annotations with natural language instructions, generates training data tailored for domain-specific tasks, and minimizes the need for prompt engineering or manual data creation.

HD Mask Rendering
Rendering pixel-accurate semantic segmentation masks over arbitrary-length video in real-time web applications presents significant technical challenges in synchronization, performance, and memory management.
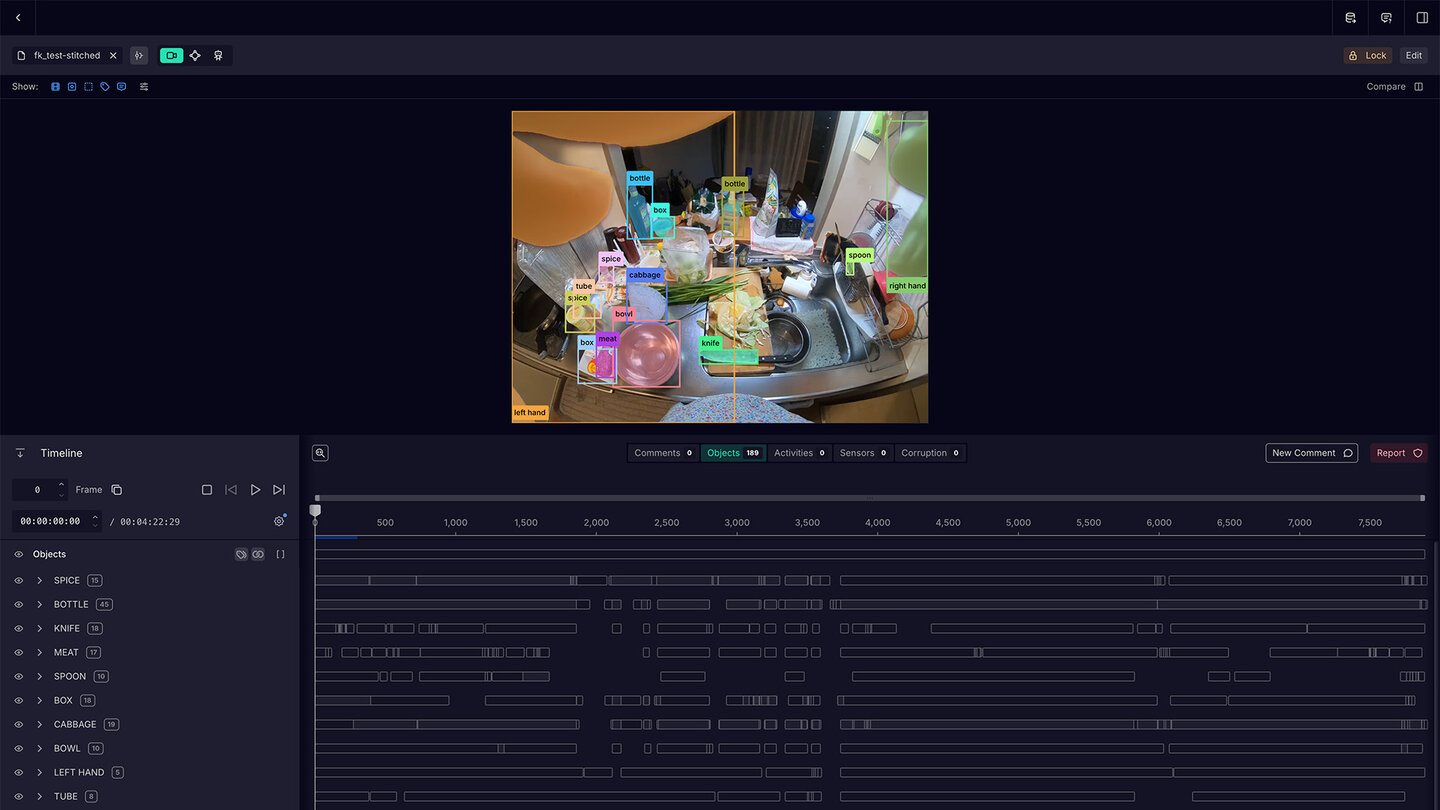
Coffee-Making 101 (for Robots)
Detailed and versatile annotations, structured activity and process understanding, integration with VLMs, and instruction generation enable and facilitate unparalleled opportunities for real-world robotic workflows and training.
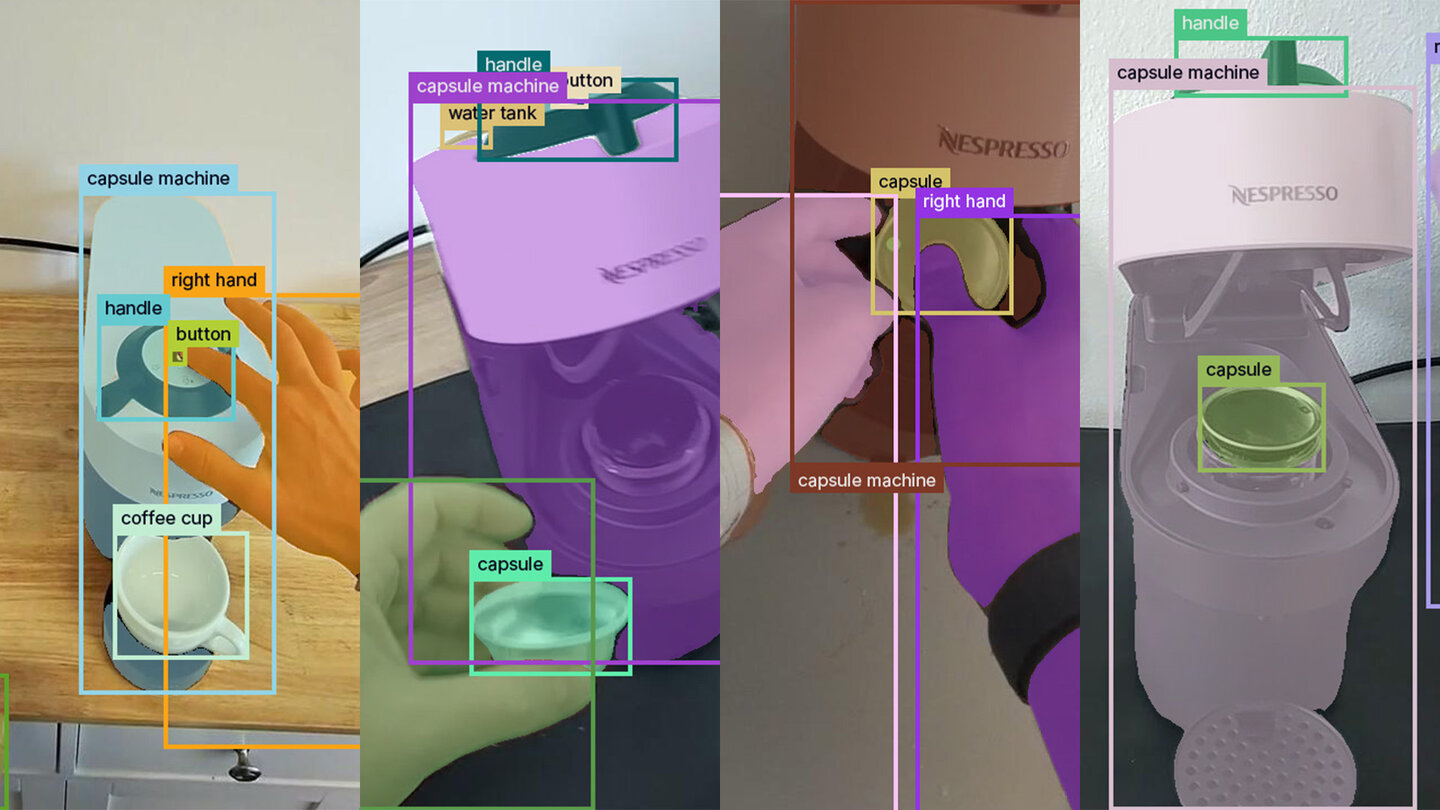
Detector Training
Training our detection architectures on our full Coffee-Making 101 dataset and also a more specific subset, demonstrates that high-quality annotations result in high-accuracy object detectors.
Activity Prediction with XGBoost
Ramblr's XGBoost-base activity predictor combines a powerful video encoder with a lightweight boosted trees classifier, enabling fast, high-performance activity prediction for domain-specific applications.

GLobal OBject Embedder (GLOBE)
Ramblr's GLobal OBject Embedder (GLOBE) leverages binary masks to isolate and encode object regions, enabling robust global identification across time and transformations.
