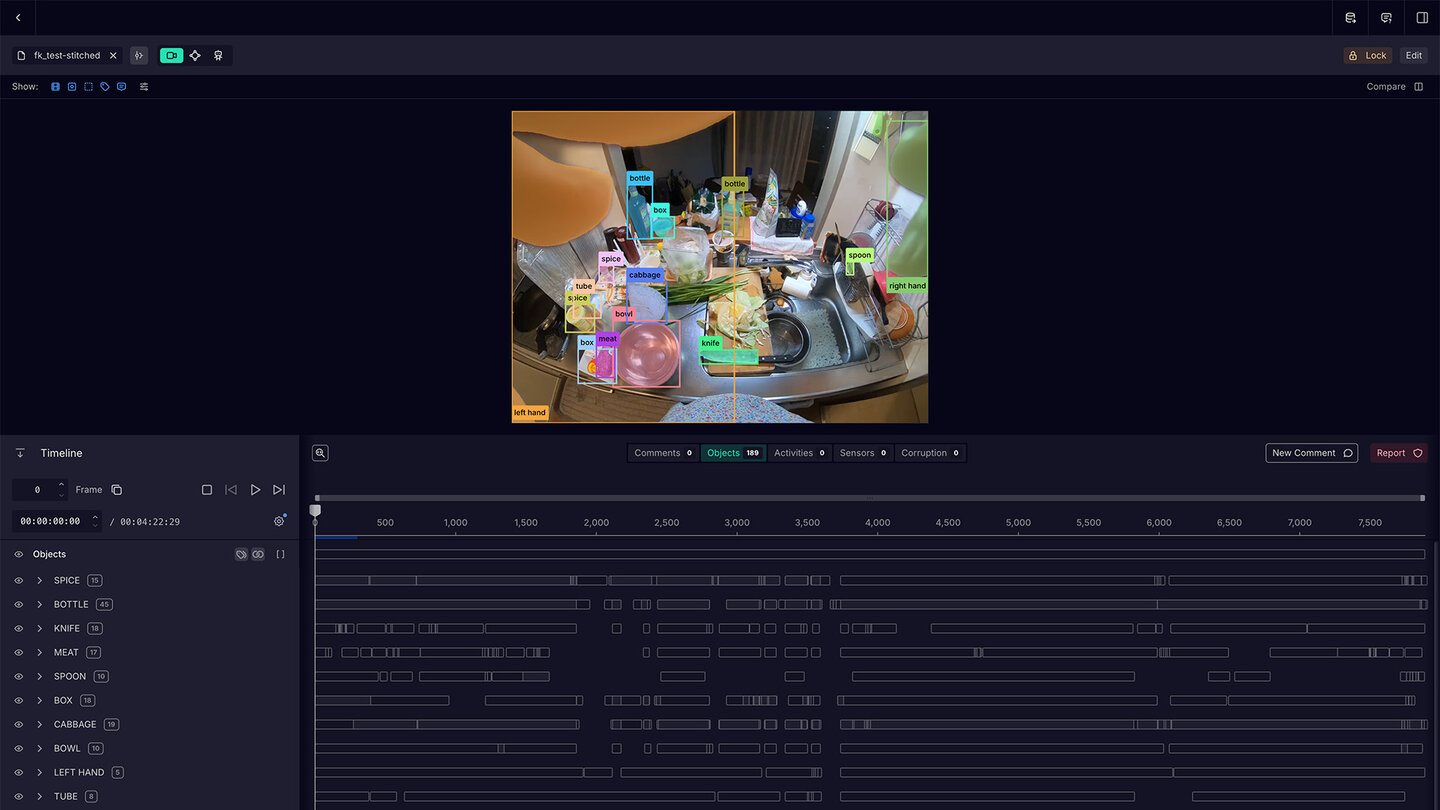
Rendering pixel-accurate semantic segmentation masks over arbitrary-length video in real-time web applications presents significant technical challenges in synchronization, performance, and memory management.
Abstract
This article details Ramblr's approach to achieving smooth 60fps mask overlay rendering while maintaining full interactive flexibility for annotation workflows. We address frame-to-overlay synchronization through precise frame indexing and modern browser APIs, implement a custom buffering strategy optimized for non-linear video navigation patterns, and employ WebWorker-based processing pipelines with SharedArrayBuffers to handle intensive mask decoding operations. Our solution converts pixel-accurate bit masks to path representations for efficient storage and rendering, enabling responsive interaction with high-resolution, long-form video content directly in the browser without pre-rendering limitations.
Introduction
At Ramblr we use dense semantic segmentation of videos as the base for our video intelligence capabilities. Those segmentations are stored in the form of bit masks for each annotated object on each annotated frame. Even with smart data formats, such as the COCO run-length-encoded (RLE) masks, fetching these masks from a server and drawing them onto a video at 60fps is a technical challenge.
We decided early that we want to combine the precision of pixel-accurate masks with full interactive flexibility in our web-based frontend. Features like hiding individual masks or changing coloring schemes exclude any sort of pre-rendering.
The rest of the article highlights some of the challenges and learnings along the way.
Methods
Rendering masks onto arbitrary length video in a web application poses three interlinked challenges:
- Synchronicity: Rendering the correct overlay onto the correct video frame.
- Speed: Rendering overlays fast enough for the video’s native fps rate to ensure smooth playback.
- Memory usage: Arbitrary-length HD or UHD video masks consume large amounts of memory if handled naively.
Synchronicity
A common approach to painting overlays on top of videos is grabbing the video frame content from the <video> element, picking the correct overlay for the video’s timestamp and then rendering both to a <canvas>. The main challenge here lies in picking the correct time for the frame grabbed from the video element. Any miscalculations or delays will result in a visible shift between overlayed masks and video content. This is most noticeable in fast paced videos.
Figure 1: Matching video frame and overlay

We found that storing masks by frame index is the most accurate for later referencing. This means that the backend and frontend need the exact same understanding how to convert between media time and frame index. As a baseline, we convert all videos to use fixed fps. We then provide the fps to our tools for conversions.
In our first prototypes we used a requestAnimationFrame callback to inspect the video's currentTime, calculate the frame index and pick the correct overlay. This turned out to be too inaccurate due to mismatches between callback intervals, callback processing time and the reported currentTime. We later changed to the much more accurate requestVideoFrameCallback (see MDN). This callback gives us an exact media time for the frame that will be presented next. We then store the frame from the video element plus it’s frame index for rendering.
Once a new frame is stored for rendering, we pick the overlay from a buffer that runs in parallel to the video. We can then draw the video together with the correct mask overlay to the HTML <canvas> element.
Apart from matching time -> frame index, we found it critical to avoid roundtrip calculations between the two. This can happen, for example, when allowing users to seek by frame index. Frame to time conversions are susceptible to one-off errors due to rounding and float precision issues. For example, at 30fps we cannot accurately represent the time for frame 2, which is 2/30 ~ 0.0666… seconds. But we need the timestamp since the browser’s video navigation is time-based. We went through a number of iterations before we had a stable version for all frame rates and different video encodings.
After selecting the correct frame, the next challenge is to render the video and overlay as quickly as possible.
Speed and Memory usage
While the browser manages video buffering and decoding, we need to implement custom logic for fetching and processing overlay data.
The primary speed bottleneck during video handling is copying pixel arrays, which affects memory management. Thus, we should analyze speed and memory together, as reducing memory usage can significantly enhance speed.
We evaluate processing speed in three stages:
- Fetching data from the server
- Decompression and transformation into the optimal rendering format
- Rendering on top of the video
Figure 2: Mask processing pipeline

For any network-bound activity, we must consider slow internet speeds and latency. Therefore, we implemented a custom buffer that fetches frames in configurable chunks and feeds them to a decoder pipeline.
The buffer is driven by the default HTML video element’s play position but employs a different heuristic. While a video player typically buffers forward in the direction of playback, video navigation during annotation tasks often involves back-and-forth comparisons of different frames. Thus, we use a custom heuristic that combines a skewed sliding window around the play position with an LRU cache for jumping between frames spaced further apart.
Figure 3: LRU + sliding window forward buffer

Once a frame range has been fetched, we need to decode the masks. We serve masks from the backend as run-length-encoded (RLE) bit masks (COCO format) over a standard REST/JSON API. While we might opt for a more specialized API in the future, we currently value the simplicity of using a singular API for metadata, editing and viewing.
The COCO masks must be decompressed from their RLE format and then transformed into a data structure that is small enough to be stored in a buffer for hundreds of frames, but fast enough to be rendered almost immediately. To speed things up we handle all these transformations in several parallel web workers that are served from a worker pool.
Figure 4: Mask decoding in WebWorkers

Performance degrades quickly when copying large pixel arrays. To manage pixel data efficiently, we use typed arrays and in-place mutations. SharedArrayBuffers allow direct transfer of pixel data between workers and the main thread, avoiding performance penalties.
Micro-optimizations in JavaScript code, particularly in loops, comparisons, and calculations, significantly enhance pixel information processing. Avoiding for .. of and Math.max() can save considerable time when iterating through thousands of frames, masks, and pixels. Benchmarking is essential.
While preserving pixel-level accuracy for mask edits is important, it is less critical during video playback. Therefore, we convert bit masks to paths for in-browser buffering and rendering. In our tests we found that drawing and filling multiple paths on an HTML <canvas> element was approximately 20 times faster than a naive approach of calling CanvasRenderingContext2D.putImageData() on prepared ImageData RGBA frames. Additionally, storing only outline paths used just 2% of the raw ImageData for a 4K test video with eight annotated objects per frame. In summary, we use RLE-encoded bit masks for server storage and editing, but convert to paths on-the-fly for playback.
Conclusions
Through iterative development, we identified key architectural decisions essential for achieving smooth 60fps mask overlay rendering. Utilizing modern browser video APIs like requestVideoFrameCallback provides accurate playback information that aligns with frame-index annotations, eliminating synchronization issues. Our WebWorker-based pipeline with SharedArrayBuffers manages intensive processing without blocking the main thread. Additionally, converting bit masks to path representations is fast enough on-the-fly, and significantly reduces memory usage and rendering time. The custom buffering strategy, which combines LRU caching with a forward-skewed sliding window, addresses unique navigation patterns in annotation workflows, where users often compare frames non-sequentially.
The result is a system that delivers responsive, interactive mask editing capabilities directly in the browser while scaling to handle high-resolution, long-form video content. Our approach maintains pixel-level annotation precision without sacrificing the interactive flexibility essential for professional annotation workflows.