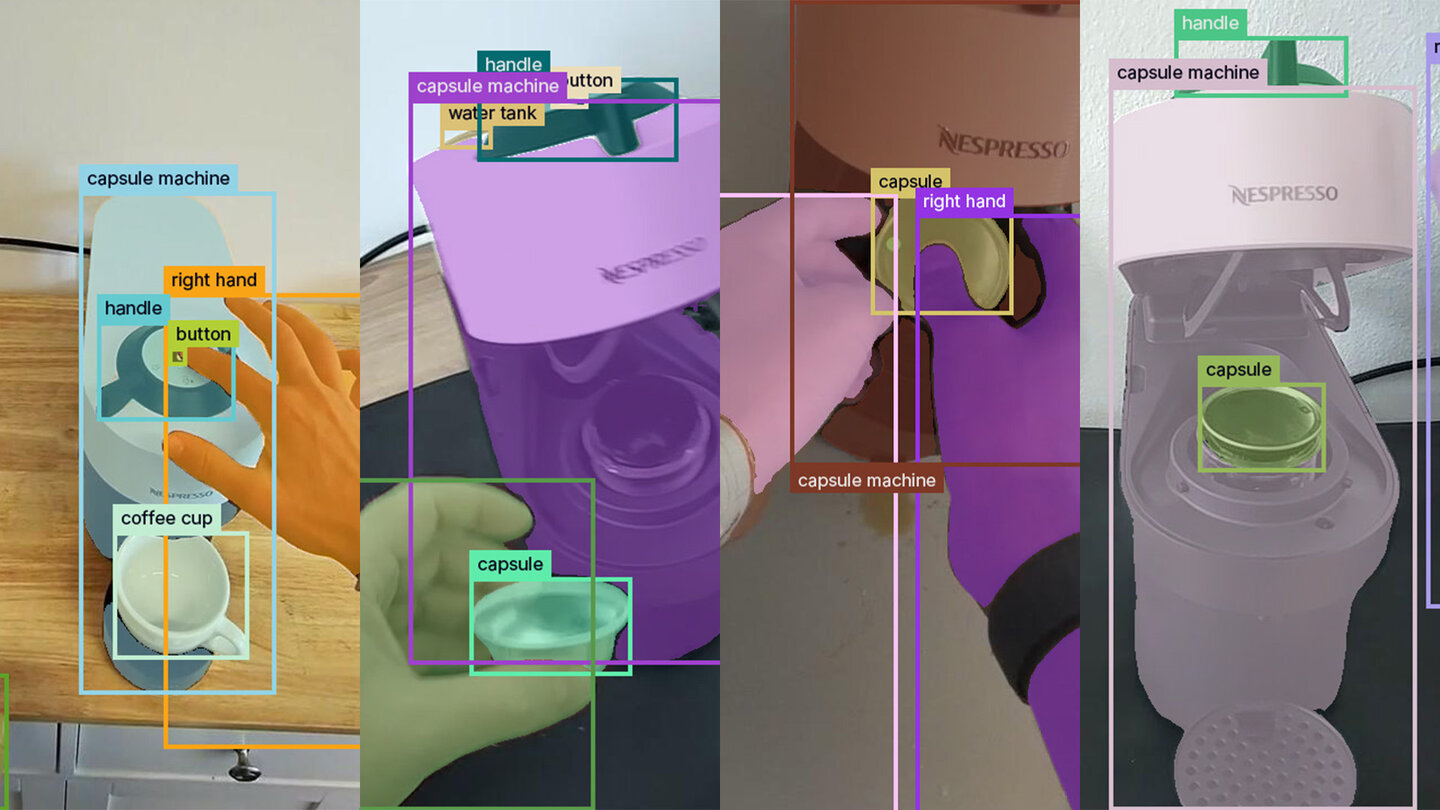
Training our detection architectures on our full Coffee-Making 101 dataset and also a more specific subset, demonstrates that high-quality annotations result in high-accuracy object detectors.
Abstract
Object detection is one of the most common tasks in computer vision: object detectors simply find the location of certain objects in an image. By training two different architectures on our Coffee-Making 101 dataset, we demonstrate that one can train high-accuracy detectors with data generated using annotations from the Ramblr Data Engine (RDE).
Introduction
Object detection is a method to detect objects in images (e.g. “car”, “human”, “cup”), essentially telling us what is present and where. Object detection models are trained to predict bounding boxes (or segmentation masks) around objects in an image. Additionally, in combination with simple object trackers, object detectors can easily be extended to videos.
Due to their simplicity, versatility and accuracy, object detectors are used in many applications across a variety of industries. Use cases range from counting passing cars on a busy road [7] to finding empty shelf spaces in a retail setting [8].
There are also open vocabulary detectors [4, 5] (so called “zero-shot” detectors), which, given a prompt, can detect objects in an image without being specifically trained for it. Such detectors typically only work on well known categories (“car”, “dog”, “person”) and fail to detect more specific categories, such as the ones found in industrial environments. For use cases that require high-accuracy, object detectors that are trained on use case-specific data are a much better alternative (e.g. in [5] it is reported that Grounding-DINO achieves AP of 52.5 with open-world detection on the COCO2017 val split, but after fine-tuning 62.6 AP).
To enable the training of detectors, the RDE can be used to efficiently and quickly annotate videos with masks and bounding boxes and export them in the COCO format, which is a standard format widely used for object detection applications. This format can also be used to train detectors from the widely known YOLO detector family [6].
Methods
The object detector in the RDE: Data annotation, automation and export
The RDE is a tool that makes uploading, annotating and finally exporting data simple and scalable.
Data annotation follows a simple paradigm that can be further automated using trained models such as detectors. First, keyframes (i.e. frames that are representative of relevant parts of the video) are chosen for annotation. Annotation is either done by a human (utilizing annotation models such as SAM2 [3]) or via automated approaches (e.g. with detectors). Next, the mask propagation capabilities of SAM2 are utilized to propagate masks and bounding boxes to all frames between the keyframes.
Once data has been annotated, it is simple to export bounding boxes and segmentation masks from the RDE in standard formats (e.g. COCO format) to train detectors and other models.
Object detectors
We train two state of the art object detector architectures
RTMDet (Real-Time Models for object Detection)
RTMDET [1] is a family of models trained for object detection and instance segmentation. It outputs both instance segmentation masks and bounding boxes, making it a good fit for various use cases.
DEIM-DETR
DEIM-DETR [2] is an advanced training framework for object detection, designed to enhance the matching mechanism in detection transformers, enabling faster convergence and improved accuracy. It only supports bounding boxes as output, but with its fast convergence rate, it becomes an essential part of workflows with many training iterations.
Dataset
We make use of the Coffee-Making 101 (for Robots) dataset, which contains video clips of a simple coffee making process performed by a human and filmed from an egocentric perspective. The dataset was richly annotated using the RDE with high quality masks, bounding boxes, categories, relations, attributes and activities. For the detector training we only make use of the bounding box and category annotations.
Mask annotation time with the RDE
In the RDE, mask annotation works by first annotating a set of smartly selected keyframes and then automatically propagating the masks from the keyframe to the rest of the video. In a final step, propagation errors may be corrected, which can be necessary for complex scenes. In the following we report statistics on keyframe annotation.
Out of the total amount of 309498 frames in the videos used only 1341 are keyframes, that is only 0.43% of the total amount of frames that need to be explicitly annotated.
Below, we report per-keyframe annotation times for the dataset used to train our detectors.
| Mean per keyframe annotation time [s] (±std) | Median per keyframe annotation time [s] (±mad) | Mean number of keyframes annotated per minute of video (± std) |
|---|---|---|
| 161 ± 129 | 120 ± 46 | 7.59 ± 2.14 |
Dataset splits
For detector training, we make use of two different splits of the dataset.
The first split consists of 66 videos for training and 28 for validation. It contains videos of different coffee machines in different environments. We trained on this dataset to show the achievable accuracy obtained when using high quality annotations from a diverse dataset. In the following, we reference this dataset as the “high diversity dataset”.
Images: high diversity dataset examples




The second split consists of 29 videos for training and 13 for validation. It contains videos of a single coffee machine model (Nespresso Vertuo Pop), but in different environments. Training on this dataset shows the accuracy one can achieve by training on highly specific data. In the following, we reference this dataset as the “specific dataset”.
Images: specific dataset examples




For validation we only use every 10th frame from the validated videos.
We limit the trainings to three categories for simplicity:
- Coffee machine
- Cup
- Human hand
The datasets have the following statistics
| Total number of frames | Total number of “coffee machine” object annotations in total | Total number of “cup” object annotations in total | Total number of “human hand” object annotations in total | |
|---|---|---|---|---|
| High diversity dataset training split | 221147 | 207863 | 212862 | 130631 |
| High diversity dataset validation split | 8838 | 8415 | 8414 | 5565 |
| Specific dataset training split | 108689 | 104468 | 88452 | 63071 |
| Specific dataset training split | 4651 | 4599 | 4060 | 2903 |
Results
Detector metrics
In statistics and information retrieval, a model’s accuracy is measured using precision. If the prediction is correct, the sample is marked as a True Positive (TP). If the prediction is inaccurate, it is marked as a False Positive (FP). Precision is computed via the following equation:
which translates to:
“Out of all the predictions the model made, what percentage of them are correct”. Precision is computed for all the data points, and averaged across the evaluation dataset, leading to the metric Average Precision (AP).
In the context of object detection, whether a prediction is a true positive or not is measured via the Intersection over Union (IoU) of the predicted bounding box and the ground truth bounding box. If the bounding boxes share a common area ratio more than an IoU threshold, and the category is correct, a prediction is counted as a True Positive in the precision computation above. IoU computation is as follows:
Furthermore, in many cases (such as in this study), there are multiple object categories. Hence, to evaluate the quality of the model for all of the categories, the individual AP values for each of the categories are averaged, leading to the metric Mean Average Precision (mAP).
For n categories, it is computed as the following:
Finally, since the determination of True Positives, and hence the outcome of the mAP depends on the chosen IoU threshold, we evaluate our models on multiple levels of strictness, using different IoU thresholds (0.25, 0.5, 0.75) to determine a correctly localized bounding box (TP), and compute individual mAP scores. We then average over all of these to report a single mAP score.
| Model | mAP (diverse dataset) | mAP (specific dataset) |
|---|---|---|
| RTMDet | 0.924 | 0.970 |
| DEIM | 0.940 | 0.977 |
One can see that the detectors deliver high accuracy throughout.
Conclusion
We have shown that data generated with the RDE can be used to train high accuracy object detectors with different levels of accuracy: The more specific the dataset is, the higher the achieved accuracy. This is important for tasks that don’t allow for much fault tolerance on specific use cases.
Annotation with the RDE is efficient and thus, can be easily utilized to generate use-case specific datasets to train object detectors or similar models.
Detectors are used in the RDE to speed up annotations, e.g. by better selection of keyframes or by auto-annotation of keyframes. Thus, with more and better data, the object detectors that we use in the annotation workflow can be retrained, gain higher accuracy and automate annotation continuously and incrementally. Management of different detectors (and other specifically trained models) is made easy by the model registry in the RDE.
References
[1] Lyu, C., Zhang, W. Huang, H., Zhou, Y., Wang, Y., Liu, Y., Zhang, S., Chen, K. (2022). RTMDet: An Empirical Study of Designing Real-Time Object Detectors. arXiv preprint arXiv:2212.07784.
[2] Huang, S., Lu, Z., Cun, X., Yu, Y., Zhou, X., Shen, X. (2024). DEIM: DETR with Improved Matching for Fast Convergence. arXiv preprint arXiv:2412.04234.
[3] Ravi, N., Gabeur, V., Hu, Y-T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K. V., Carion, N., Wu, C.-Y., Girshick, R., Dollár, P., Feichtenhofer, C. (2024). SAM 2: Segment Anything in Images and Videos. arXiv preprint arXiv:2408.00714.
[4] Minderer, M., Gritsenko, A., Houlsby, N. (2023). Scaling Open-Vocabulary Object Detection. arXiv preprint arXiv:2306.09683.
[5] Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., Zhu, J., Zhang, L. (2023). Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection. arXiv preprint arXiv:2303.05499.
[6] Ultralytics. Ultralytics YOLO11 (2024). In Ultralytics YOLO Documentation. Retrieved from Ultralytics YOLO11 overview page https://docs.ultralytics.com/models/yolo11/.
[7] Mostafa, S. A., Gaber, A., Shehata, M. (2024). Automated Vehicle Counting and Speed Estimation Using YOLOv8 and Computer Vision. Journal of Al-Azhar University Engineering Sector, 19(73), 1382-1395.
[8] Anas, N. M., Dzulqaidah, N., Ramli, A. Q., Nayan, N. M., Harun, N. H., Haron, H. (2023). Out-of-Stock Empty Space Detection Using YOLOv7 for Retail Products on Shelf for Inventory Management. In 2nd International Conference on Applied Science and Engineering (2nd ICASE23B).