Summary
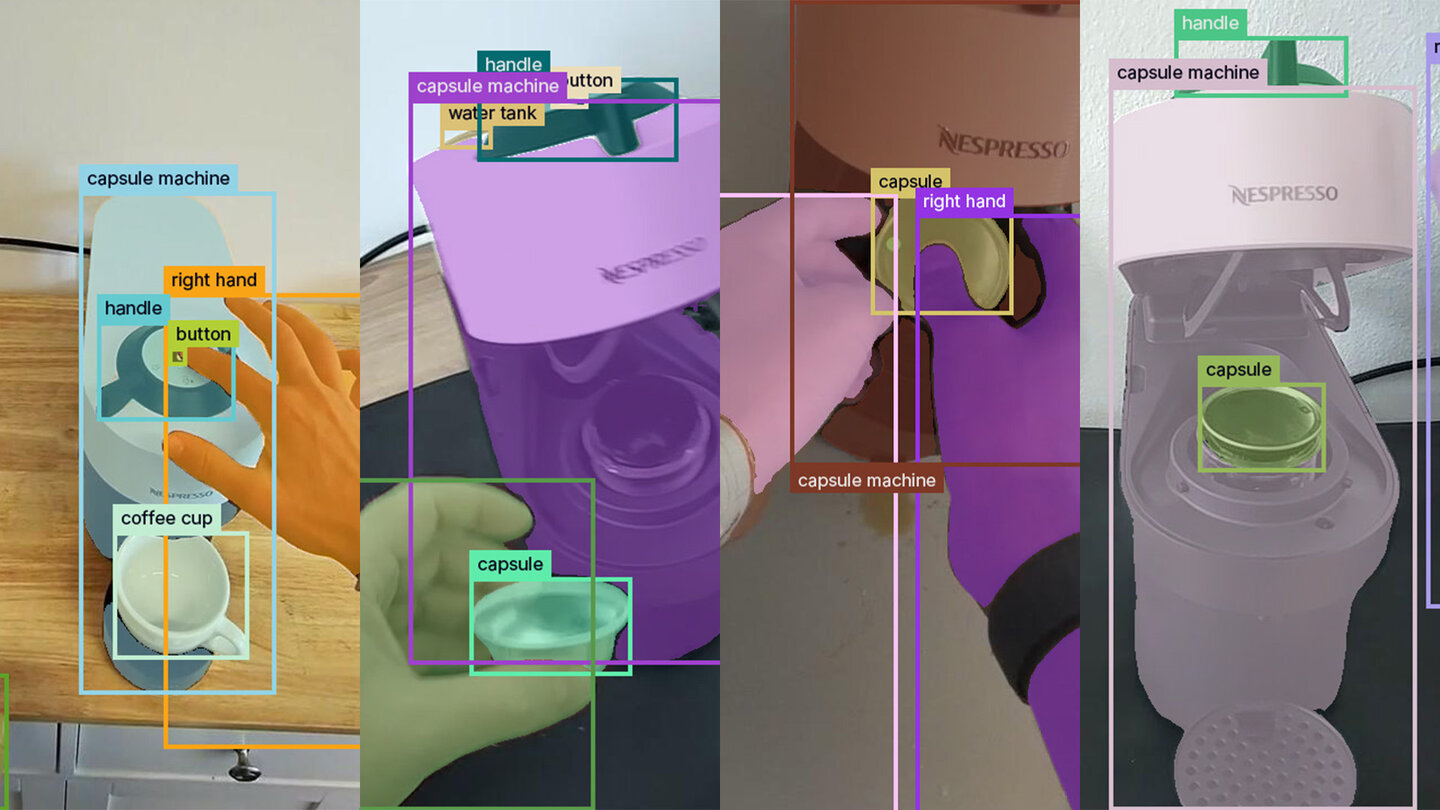
Large Language Models (LLMs) revolutionized human-computer interaction, by making complex knowledge accessible through natural language, bridging the gap between humans and machines. Current multimodal models (MLLMs) still fall short when it comes to real-world awareness. They often lack an understanding when and where something is happening – critical elements essential for interacting reliably with the real world. That’s why we’re building REACT: a fine-tuned MLLM designed to understand spatial and temporal context by analyzing video and sensor data. Our goal is to enable machines to follow and understand complex human instructions in dynamic environments.
We’re putting REACT to the test with a real-world scenario: a mobile robot that takes a coffee order directly from a person, operates the coffee machine, and serves the drink – even as conditions around it change. By combining cutting-edge AI with real-time contextual understanding, REACT takes human-machine interaction to the next level.
Goals
Spatiotemporal Contextualization
Fine-tuning MLLMs to interpret spatiotemporal sequences from multimodal inputs.
Real-Time Reasoning
Enabling fast, context-aware decision-making in dynamic environments.
Grounded Instruction Following
Translating natural language into executable steps tied to the environment.
Sensor + Video Fusion
Integrating first- and third-person video with real-world sensor data for richer scene understanding.
Autonomous Task Execution
Demonstrating end-to-end autonomy in a physical human-interaction scenario.